ML Lecture 4 Part I Feature Selection
特征选择 Feature Selection
- 定义: 特征选择是从原始数据集中识别并选择最相关、信息量最大且非冗余特征(变量)子集的过程,同时丢弃无关或嘈杂的特征 。
- 目的: 它是机器学习数据预处理的关键步骤,旨在提高模型性能、降低计算成本并增强可解释性

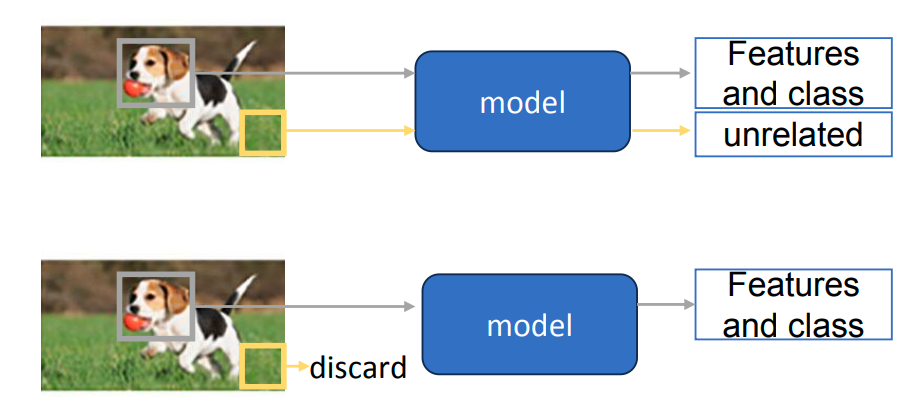 益处:
益处:
- 加速训练: 模型不需要学习无关特征 。
- 减少过拟合: 避免模型过度学习不相关的特征 。
- 提高可解释性: 确定哪些特征与任务相关 。
特征选择中的典型陷阱 Pitfalls
- 数据泄露 (Data Leakage): 在特征选择过程中误用了测试集或未来数据,导致模型评估结果虚高 inflated (这个词似乎也是通货膨胀的意思) 。
- 例子: 选择特征时忘记从数据中移除测试集特征 。
- 多重共线性 (Multicollinearity): 高度相关的特征会扭曲线性模型的权重并降低可解释性 。
- 例子: 年龄和工龄高度相关,特征选择可能难以区分谁更重要 。
- 目标泄露 (Target Leakage): 特征包含关于目标变量的间接信息 。
- 例子: 用个人行为预测年龄时,使用了“出生日期”作为特征 。
- 忽略特征交互 (Ignoring Feature Interactions): 单独移除看似无关的特征,导致丢失组合特征的价值 。
- 例子: 忽略了年龄和收入组合对购买力的影响 。
| 特征选择方法 | 主要思想 | 特点 |
|---|---|---|
| 过滤法(Filtering method) | 在训练任何模型之前,利用统计评分(如相关系数或方差)快速挑选出最优特征。 | 速度快、实现简单,但忽略特征之间的相互作用。 |
| 包裹式方法(Wrapper method) | 通过反复训练/测试模型来评估特征子集(如前向选择、递归特征消除 RFE)。 | 比过滤法更准确,但计算开销更大、速度更慢。 |
| 嵌入式方法(Embedded method) | 在模型训练过程中同时完成特征选择(如 L1 正则化、基于树模型的特征重要性)。 | 通过在训练时学习特征重要性,在速度和 |
特征选择:过滤法 Filter Method
原理: 利用统计方法检查特征 。
优点:
- 模型无关: 不依赖任何机器学习算法 。
- 计算效率高: 基于数据本身的统计特性进行过滤,适合高维数据的初步过滤(如基因数据和文本特征)。
缺点:
- 忽略特征交互: 单变量统计无法充分考虑变量间的相互作用 。
- 捕捉非线性关系能力有限: 简单的统计量无法过滤非线性特征,需要更复杂的方法 。
常用过滤法
- 方差阈值法 (Variance threshold method) 。
- 单变量统计检验 - 卡方检验 (Chi-squared test) 。
- 单变量统计检验 - F检验 (F-test) 。
- 互信息法 (Mutual information method) 。
方差阈值法
- 原理: 移除方差低于阈值的特征;这些特征被视为常量特征或近似常量特征。
- 公式:
- 注意: 方差阈值对特征尺度敏感,不能在不了解量纲的情况下直接比较不同单位特征的方差;若先做标准化,所有非恒定特征方差会接近 1,反而会削弱该方法删除低方差特征的作用。
在特征选择中,高方差说明该特征在样本间取值差异大,具备一定的区分潜力,但并不必然与标签相关,因此“高方差 ≠ 一定有用”;相反,低方差特征在所有样本上几乎恒定,通常携带的信息极少,难以帮助模型区分样本,所以常通过如 Variance Threshold 这类方法先被删除,以降低维度、减少计算量、缓解过拟合并让模型更易解释。
不过需要注意:低方差特征有时仍可能与标签强相关(例如少数异常值几乎必然对应阳性),此时机械删除是危险的;同时,标准化会改变方差大小,因此一般应先按方差筛选再做标准化;对 one-hot 特征也不能只看方差大小,还要结合业务和标签信息综合判断。
总体来说,高方差特征意味着“可能更有信息量”,移除低方差特征主要是清理几乎无信息的特征,但最终是否保留某个特征还应结合标签相关性和具体场景共同决定。
单变量统计检验:卡方检验 Univariate statistical tests: chi-squared test
- 原理: 通过测试特征与目标变量之间的独立性来过滤重要特征。
- 步骤:
- 确定假设:
(特征独立于目标), (特征与目标相关)。 - 计算统计量:
是观测频率, 是假设特征与目标独立的理论频率。 - 判断:
越大,特征与目标的相关性越强。根据显著性水平确定临界值。
- 确定假设:
卡方检验 - 示例
- 案例: 研究性别(Gender)与饮料偏好(茶/咖啡)是否相关。
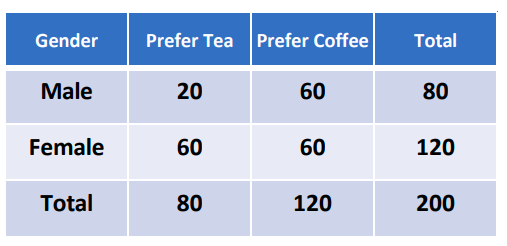
- 样本: 200名参与者。
- 数据: 男性偏好茶60人/咖啡20人;女性偏好茶60人/咖啡60人。
- 计算
- 期望频率
。 - 卡方值
- 结论: 拒绝
,性别与饮料偏好之间存在统计学显著关系。
实施步骤
- 连续变量分箱 Continuous variable binning: 如果数据是连续的,将其转换为离散区间(每个箱的期望频率应不小于5) 。
- 计算统计量: 应用卡方检验 。
- 特征选择:
- 方法1:对统计量排序,保留前 K 个特征 。
- 方法2:设定显著性水平,保留落在拒绝域内的特征 。
单变量统计检验:F检验
- F检验: 用于数值特征。
- 原理: 通过分析组间方差和组内方差的差异来评估特征重要性。
- 假设:
(特征独立于目标,均值相同), (特征相关,至少有一组均值不同)。 - 计算检验统计量
其中,
各符号含义为:
:第 个类别的样本数量 :第 个类别的特征均值 :所有数据的总体均值 :第 个类别中第 个样本的特征取值
判断: F值越大,相关性越强。
步骤:
- 计算测试统计量(应用F检验) 。
- 根据预设条件选择特征:
- 方法1:排序,保留前 K 个 。
- 方法2:设定显著性水平,保留符合条件的特征 。
互信息法 Mutual Information
- 定义: 互信息(Mutual Information)是一种基于过滤的特征选择方法,建立在信息论的基础上,用于度量特征与目标变量之间的统计依赖关系(包括线性和非线性关系)。
: 与 的联合分布(joint distribution) 、 : 与 的边缘分布(marginal distributions)
物理意义:表示在已知特征
特征选择:包裹法 Wrapper Method
常用包裹法
- 前向选择 (Forward Selection) 。
- 后向消除 (Backward Elimination) 。
- 递归特征消除 (Recursive Feature Elimination, RFE) 。
优点:
- 模型性能导向: 基于模型性能选择,结果高度可靠 。
- 模型无关 (Model-agnostic): 适用于任何模型 。
缺点:
- 计算成本高: 需要重复训练模型,不适合大规模数据集 。
- 潜在过拟合: 选择过程完全依赖数据特征,可能导致对训练数据过拟合 。
包裹法:向前选择 Forward Selection
步骤:
- 初始化: 空集
,评估指标。 - 迭代: 对每个特征
,用 - 选择最佳: 选出性能最好的特征
加入 ,从 中移除。 - 重复: 直到满足终止条件(如达到特征数量 k 或性能提升不足)。
- 优点: 计算量相对其他包裹法较少(尽管仍需重复训练) 。
- 缺点: 类似贪心算法,容易受局部选择影响,选出的集合可能不是全局最优的 。
包裹法:后向消除 Backword Elimination
步骤:
- 初始化: 选择集
包含所有特征。 - 训练: 使用当前
训练并评估。 - 评估重要性: 尝试移除每个特征
,计算性能差异 。 - 更新: 移除性能损失最小(或提升最大)的特征。
- 重复: 直到满足终止条件。
- 优点: 更好地平衡了效率和效果,适合高维数据。
- 缺点: 依赖模型能力。如果模型不能完全学习特征,可能会错误消除某些特征。
包裹法:递归特征消除 RFE recursive feature elimination
步骤:
- 初始化: 全特征集
,基模型(如SVM),重要性指标 Importance Matric。 - 训练基模型: 获得特征重要性。
- 排序: 按重要性排序。
- 更新: 剔除排名最后的 r 个特征。
- 重复: 直到满足条件。
- 优点: 比穷举搜索更高效,若基模型能表达特征交互,则可在一定程度上利用特征相关性;也可以选择与最终模型不同的基模型。
- 缺点: 依赖模型可解释性(基模型必须能给出重要性)。
特征选择:嵌入法 Embedded Method
常用嵌入法
线性回归: 正则化方法 (Regularization method) 。
树模型: 决策树特征重要性 (Decision tree feature importance) 。
深度学习: 注意力机制 (Attention mechanism) 。
特点: 在模型训练过程中进行特征选择 。
优点:
- 高效率: 只需训练一次 。
- 更好的适应性: 特征选择依赖于具体算法 。
缺点:
- 缺乏可解释性: 复杂模型的重要性难以解释 。
- 难以检测错误: 错误只能反映在模型性能上 。
线性回归:正则化方法 Regularization Method
回顾线性回归
给定数据
其中,
其中:
用来消除样本数量对数值大小的影响; 用来抵消求导时产生的系数 2,从而简化计算; - 平方项
之后,我们可以使用各种优化方法来最小化上述目标函数。
L1 正则化 L1 Regularization
作为一种典型方法,L1 正则化在原始优化目标中加入一个额外的正则项:
显然,当
Step 1:对特征做缩放,且只在训练集上拟合缩放器,再用于验证集/测试集,保证数值尺度一致并避免数据泄露。
Step 2:确定一个
Step 3:训练模型。使用新的优化目标来训练模型,系数
在机器学习和统计中,“正则(正则化)”指的是在训练过程中给模型加约束、惩罚其过度复杂的做法,用来防止过拟合、提高泛化能力。没有正则时,模型会一味追求在训练集上误差最小,容易“记住”噪声;加入正则后,模型需要在“拟合训练数据好”和“保持足够简单”之间做权衡,从而在新数据上表现更稳健。
“正则项”则是加在目标函数(损失函数)里的那一部分惩罚模型复杂度的数学表达式,例如
(L1 正则)或 (L2 正则)。目标函数通常写成“数据误差项 + 正则项”,前者衡量模型对训练数据的拟合程度,后者惩罚参数过大或模型过于复杂;其中系数 控制正则化强度,决定更偏重“拟合好”还是“更简单”。
L1 正则化分析
L1 正则化实现特征选择的原因:
当原始目标函数的等高线与 L1 约束域相切时,相切点往往出现在多面体的顶点位置,这意味着至少有一个系数
下图给出了二维情形(
Page 34: L1 正则化优缺点
| 优点 | 缺点 |
|---|---|
| 自动特征选择 | 对于高度相关的特征可能只随机选一个 |
| 计算效率高(适合高维) | 需要特征缩放 |
| 提供系数可解释性 | 仅适用于线性模型 |
树模型 Tree Model
回顾决策树 Decision Tree:
- 选择特征分裂数据(ID3, CART等) 。
- 直到满足条件(如叶节点纯度、最大深度)停止 。
- (可选)剪枝 。
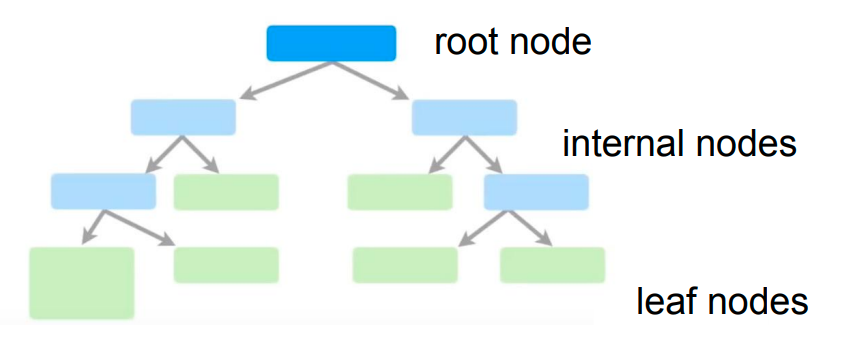
决策树特征重要性
给定数据
其中,
其中,
根据计算出的特征重要性,可以设定阈值来筛选特征,或者直接选择重要性排名前
例 数据)在根结点上的二分类样本:正类 30 个,负类 10 个(共 40 个)。
假设某一次划分产生如下结果:
左子结点:正类 24,负类 6,则
右子结点:正类 6,负类 4,则
划分后的加权不纯度为:
不纯度降低量为:
如果在所有候选划分中,这个不纯度下降量最大,则选择这一次划分。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 自动捕捉非线性关系 | 对特征与标签相关性较为敏感 |
| 计算效率高 | 倾向于选择基数较高的特征(高基数) |