ML Lecture 4 Part II Dimension Reduction
高级数据预处理:降维 Dimension Reduction
定义: 利用数学或统计方法将高维数据转换为低维表示 。
目的: 尽可能保留原始数据关键信息,降低复杂性,提高效率 。
与特征选择的区别: 特征选择直接丢弃特征,如果所有特征都重要会导致性能下降,因此需要降维(特征组合/转换) 。
缓解“维数灾难”: 增加数据密度,提高泛化能力 。
- 现象: 随着维数增加,样本变得更容易区分,但由于样本数量没有增加,数据变得稀疏,导致模型容易过拟合 。
提高计算效率: 加速训练,优化算法在低维空间更高效 。
去除噪声和冗余: 移除无关特征,合并相关特征 。
改善可视化: 将数据降至 2D/3D 以便观察 。
增强可解释性: 如 PCA 主成分可解释为“综合指标” 。
协方差矩阵 (Covariance Matrix): 描述变量间的相关性。
特征分解 (Eigen-decomposition):
奇异值分解 (Singular Value Decomposition, SVD):
降维的评估
保留方差比例(Retained variance ratio)
:原始数据 :降维后的数据
重构误差(Reconstruction Error)
:原始数据 :重构后的数据 :误差度量,如 MSE、MAE 等
下游任务表现(Downstream task performance) 例如:使用降维后的数据进行识别任务时的分类/识别准确率。
潜在的误解 potential misconceptions
“降维一定会提升模型性能?”
降维有时只会提升计算效率,反而可能使预测准确率下降。“降维后保留的主成分都可以被直接解释?”
通过降维方法保留下来的某些特征,在语义上可能难以解释。
线性与非线性降维 Linear and non-linear dimensionality reduction
线性降维
通过寻找一个线性变换(原特征空间的线性组合),将数据映射到一个低维子空间中。
常见方法包括:主成分分析(PCA)、线性判别分析(LDA)、奇异值分解(SVD)等。
非线性降维
利用非线性变换对数据进行建模或映射,从而在低维空间中获得数据表示。
常见方法包括:核 PCA、局部线性嵌入(LLE)、t 分布随机邻域嵌入(t-SNE)、变分自编码器(VAE)等。
线性降维:主成分分析 Principal Component Analysis
PCA 原理
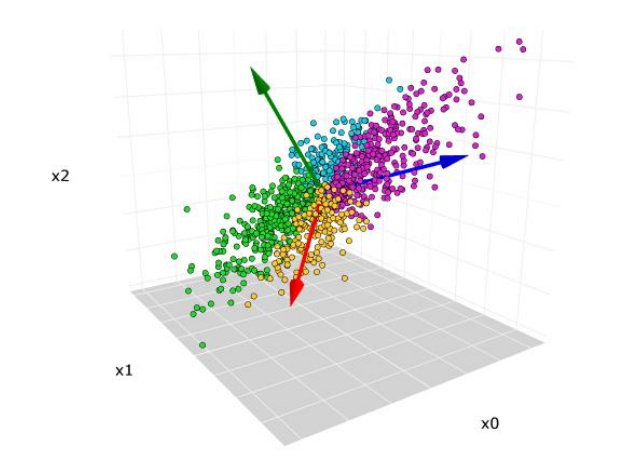
- 核心思想: 寻找一组新的正交方向(主成分),使数据投影到这些方向后的方差尽可能大。
- 操作: 按解释方差从大到小选择前几个主成分;主成分通常是原始特征的线性组合,而不是简单选择原始维度。
PCA 操作
Step 1 中心化
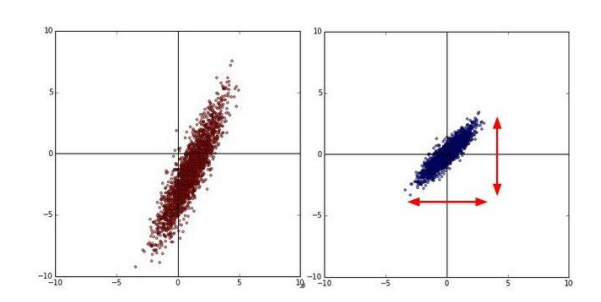
- 公式:
- 目的: 消除均值偏移,使 PCA 捕捉围绕均值的方差结构。中心化不会消除不同特征的量纲差异;若特征尺度差异很大,通常还需要先进行标准化。
Step 2 计算协方差矩阵
- 公式:
- 含义: 对角线是方差,非对角线是协方差。
协方差矩阵
由于在数据中心化后,所有维度的均值已经被调整为 0,因此可以直接使用上述形式来计算协方差矩阵。
Step 3 特征分解 Conducting Eigen-Decomposition
对协方差矩阵做特征分解:
是一个 是一个特征向量(即一个主成分的方向); 是对角矩阵,对角线上的元素 为对应的特征值。
特征值的大小表示该主成分所携带的方差信息量。
如何得到
得到各个特征值
可以得到对应的特征向量
Step 4 选择主成分
将所有特征值及其对应的特征向量按照特征值从大到小排序。
特征值
为每个主成分计算其解释方差比(Explained Variance Ratio,EVR):
根据需求选择前
典型的
- 直接指定一个固定的降维维度,将其设为
; - 指定一个“原始方差保留率”,选取前
个主成分,使得累计 EVR 达到该保留率; - 绘制特征值大小的折线图(scree plot),在“拐点”处选择合适的
。
Step 5:数据映射(降维) Mapping the data, dimensionality reduction
利用选取出的特征向量构造映射矩阵
其中,
评价
优点
- 去噪(Denoising): 较小的主成分往往对应噪声,去除这些主成分可以提高信噪比。
- 避免冗余(Avoiding redundancy): 各主成分方向两两正交,意味着新特征之间完全不相关,减少了冗余信息。
缺点
- 可解释性降低(Decreased interpretability): 主成分是原始特征的线性组合,其物理含义可能变得不直观、不易解释。
- 依赖方差(Dependence on variance): 该方法倾向于保留方差较大的特征方向。如果存在方差较小但非常重要的特征,它们可能在降维过程中被舍弃。
线性降维:线性判别分析 Linear Discriminant Analysis
找到一个低维线性投影空间,使得所有数据点投影后满足: 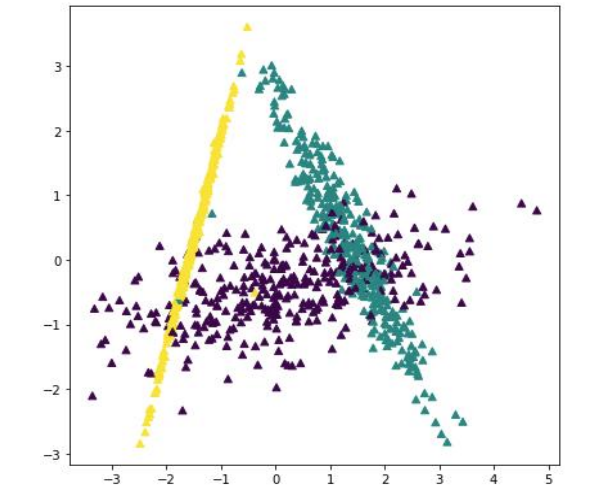
- 最大化类间间隔(Maximize inter-class separation):不同类别数据在该直线上的投影尽可能远。
- 最小化类内方差(Minimize intra-class variance):同一类别的数据在该直线上的投影尽可能聚得很紧。
LDA 的目标就是寻找这样一个最优投影方向,在该方向上线性投影后,不同类别的数据尽可能分开。
Step 1 计算各类的均值向量(Calculating the means)
设
为每一类计算其均值向量
Step 2:计算散度矩阵(Calculating the scatter matrices)
类内散度矩阵(Within-class scatter matrix):
类间散度矩阵(Between-class scatter matrix):
其中:
:类别数(number of categories) :第 个类别中的样本集合 :第 个类别的样本数量
Step 3 构造目标矩阵(Calculating the objective)
Step 4:特征分解(Eigen-decomposition)
对矩阵
Step 5 选择投影方向(Select the projection direction)
将特征值按从大到小排序,选取前
Step 6 数据映射(降维)(Mapping the data, dimensionality reduction)
其中,
Step 7(选):在新数据上进行分类(Classifying based on new data)
一种典型方法:
- 计算每一类在投影空间中的中心点
; - 对于一个新样本
,先进行投影: - 使用分类器(例如最近中心分类器),预测其类别:
Advantages(优点)
- 有监督学习(Supervised): 在降维过程中显式利用类别标签信息,相比无监督方法,通常能在分类任务上获得更好的降维效果。
- 可解释性较强(Interpretability): 投影方向(特征向量)代表了最具判别力的特征组合。
Disadvantages(缺点)
- 依赖分布假设(Reliance on distributional assumptions): 作为分类器使用时,LDA 通常假设各类近似高斯分布且协方差相同;作为 Fisher 判别式降维时,这一假设不是计算投影方向的必要条件,但若数据分布严重偏离,分类效果可能下降。
- 对离群点敏感(Sensitivity to outliers): 均值和散度矩阵的计算很容易受到异常点的影响。
PCA 与 LDA 的区别
| Aspect(方面) | PCA | LDA |
|---|---|---|
| Learning Type(学习类型) | 无监督学习(Unsupervised learning,标签不需要) | 有监督学习(Supervised learning,需要标签) |
| Optimization Objective(优化目标) | 最大化数据方差,尽可能保留“总体信息量” | 最大化类间可分性,使不同类别更加可分(inter-class discrimination) |
| Dimensionality Reduction Limit(降维维度上限) | 最多保留 | 最高只能降到 |
| Application Focus(应用侧重点) | 通用降维、去噪与可视化 | 用于特征提取和面向分类任务的降维 |
| Effect(效果) | 更清晰地展示数据的全局结构 | 更强的类别分离效果,增强类间区分 |
线性降维:奇异值分解 Singular Value Decomposition, SVD
任意矩阵都可以看作是对数据的一种“视角”(例如原始特征维度)。
SVD 的目标是找到一组新的、更本质的正交基,从这些新视角重新描述数据,从而揭示其内部结构。 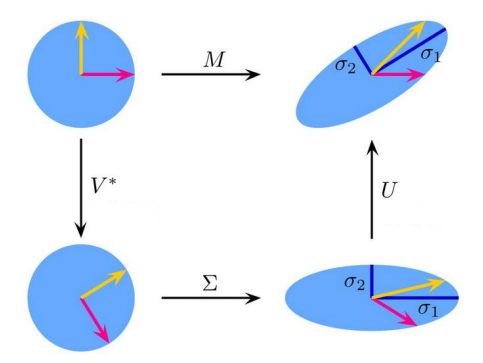
Step 1 中心化(Centering,用 SVD 实现 PCA 时)
设
其中
目的:消除均值偏移,使后续 SVD 捕捉到的主要是“方差结构”而不是均值偏移。SVD 本身可直接分解任意矩阵;这里的中心化是为了让它与 PCA 的目标一致。
Step 2 进行奇异值分解
: : :对角矩阵(diagonal matrix),对角线元素为矩阵 的奇异值(singular values),可能存在全零的行或列。
一种实现方式:
- 计算
并对其做特征分解; - 得到的特征向量可用于构造
和 ,对应的特征值的平方根即为 的奇异值。
Step 3 选择目标维度数 Selecting a target dimension number
计算前
奇异值平方
前
通常选择最小的
另一种做法是使用 scree plot:
绘制奇异值随排序的下降曲线,在“拐点”处选择合适的
Step 4 数据映射(降维)
方法 1:投影到右奇异向量上(在特征空间中降维)
其中
这是最常用的方法。
方法 2:直接使用左奇异向量和奇异值
该结果与方法 1 完全等价,
SVD 的优缺点
Advantages(优点)
- 数值稳定性强(Numerical stability):是求解线性代数问题最稳定、最可靠的方法之一。
- 适用性广(Strong universality):适用于任意矩阵,不要求矩阵是方阵或满秩。
- 最佳近似性质(Best approximation):Eckart–Young–Mirsky 定理保证,截断 SVD 在 Frobenius 范数意义下给出了原矩阵的最佳低秩近似。
Disadvantages(缺点)
- 计算成本高(High computational cost):对大矩阵做完整 SVD 的计算代价很高,不过可以使用随机/截断 SVD 算法降低开销。
- 可解释性较弱(Low interpretability):新的潜在特征通常是原始特征的线性组合,其物理含义可能不直观。
- 线性假设(Linear assumption):只能捕捉数据中的线性结构和模式,对强非线性结构的表达能力有限。
PCA 与 SVD 的区别与联系
演示:
- 未中心化的数据直接做 SVD 会受均值影响 。
- PCA 先中心化再分解,真正找到方差方向 。
联系: 对中心化的数据矩阵 A 进行 SVD,其右奇异矩阵 V 就是 PCA 的主成分方向 。
主要区别: SVD 是矩阵分解方法,可用于任意矩阵;PCA 是一种降维/统计分析方法,既可以通过协方差矩阵的特征分解实现,也可以通过对中心化数据矩阵做 SVD 实现。